Intro to R Part 3:
Data Wrangling
Andy
Lyons
October 11, 2023
Andy
Lyons
October 11, 2023
![]()
“Base R” comes with some basic plot functions:
hist(x)
boxplot(x)
plot(x, y) ## scatterplot
plot(x, y, type = 'b') ## 'b' = plot both points and lines
There are packages designing specifically for plotting (e.g.,
ggplot2)
packages are the key to productivity with R
packages mainly provide additional functions (and sometimes data)
the tidyverse is a family of packages for working with data
you can install packages from the ‘Packages’ pane in
RStudio, or install.packages()
load packages into memory with
library()
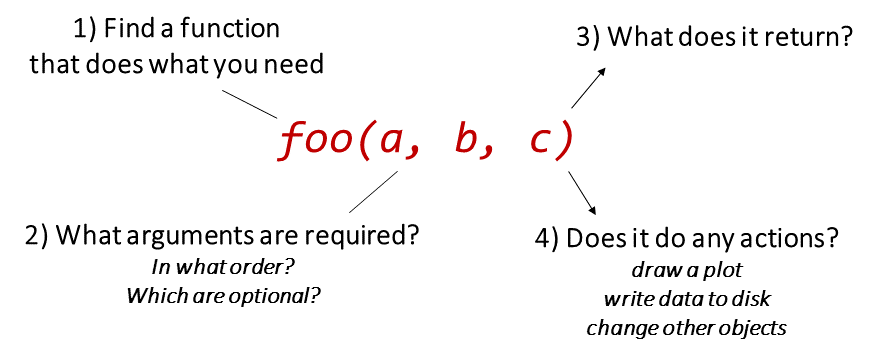
fun_a() |> fun_b() |> fun_c() |> …
iris |> filter(Sepal.Length > 7) |> mutate(width_length = Sepal.Width * Sepal.Length)
│ │ │
│ │ └─ create a new column
│ │
│ ├─ select those rows where Sepal.Length > 7
│ └─ don't have to specify the data frame
│
└ start with this data frame
The most common class for storing tabular data in R is the data frame
View the first few rows of a data frame with
head()
View an entire data frame with
View()
Grab an individual column with $
Base R function for importing csv files: read.csv()
RStudio also has an import dataset wizard
Packages available for importing specific file formats (e.g., SPSS)
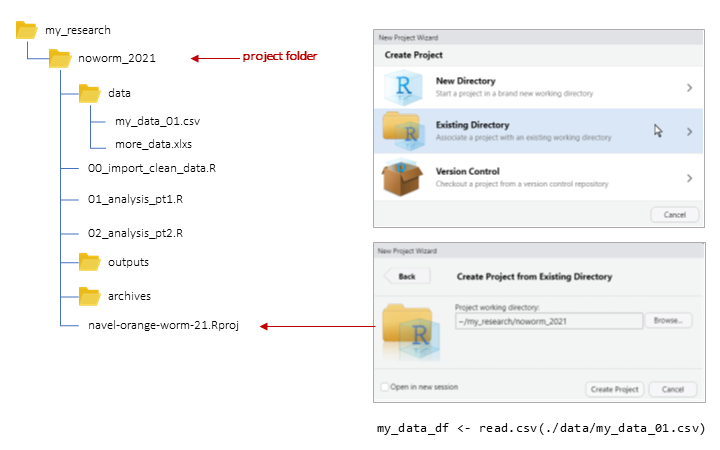
Paths to files can be absolute or relative (to the working directory)
Best practice for reproducibility and portability: RStudio projects
Whatever is needed to get your data frame ready
for the function(s) you want to use for analysis and visualization.

also called data munging, manipulation, transformation, etc.
Often includes one or more of:
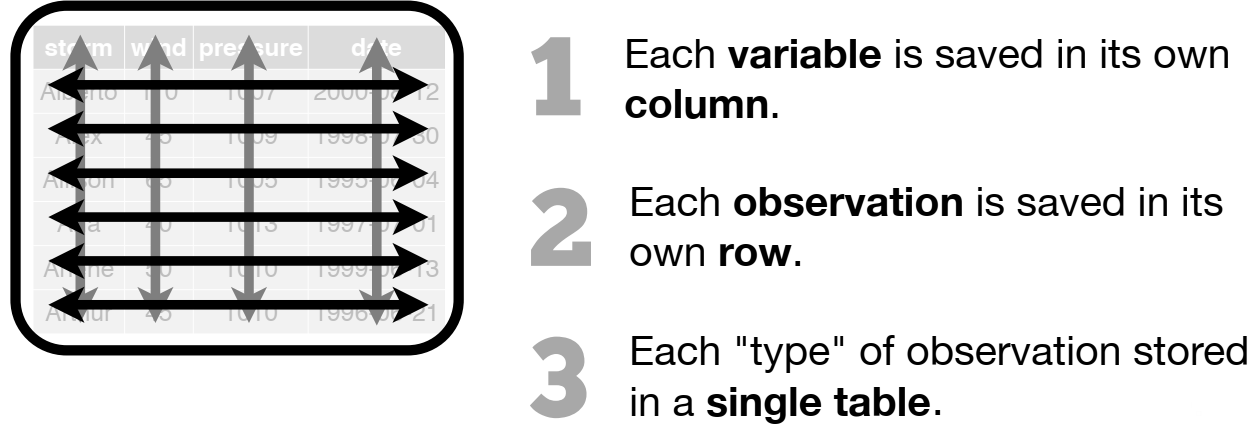
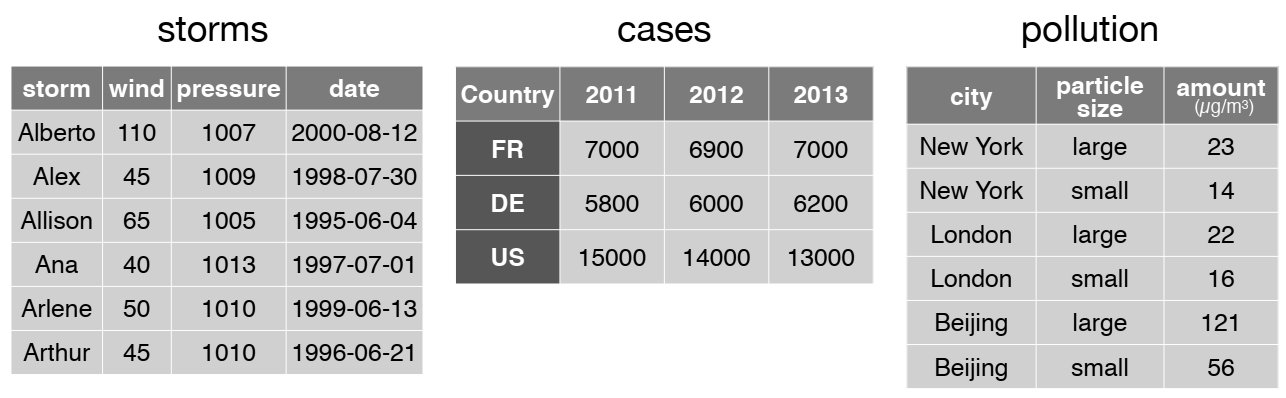
R functions like tidy data!
![]()
![]()

The functions in these packages allow you to:
Example:

dplyr![]()
An alternative (usually better) way to wrangle data frames than base R.
Part of the tidyverse.
Best way to familiarize yourself - explore the cheat sheet:
![]()
Occasionally two or more packages will have a function with the same
name. 
R will use whichever one was loaded first.
Best practice: use the package name and the :: reference
to specify which package a function is from.
When you use the package_name::function_name
syntax, you don’t actually have to first load the package with
library().
Resolving Name Conflicts with the conflicted
Package
When you call a function that exists in multiple packages, R uses whichever package was loaded first.
The conflicted package helps you avoid problems with
duplicate function names, by specifying which one to prioritize no
matter what order they were loaded.
R Notebooks are written in “R Markdown”, which combines text and R code.
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
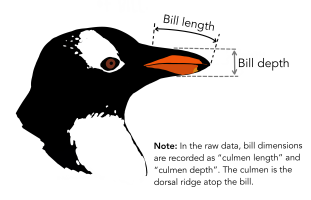
We’ll be looking at the Palmer Penguins dataset.
![]()
This exercise will be R Notebook!
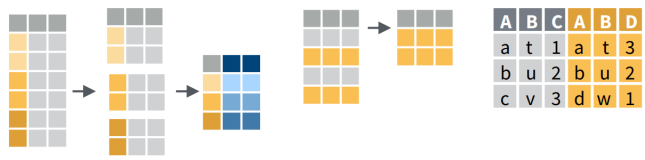
| join data frames on a column | left_join(), right_join(), inner_join() |
| stack data frames | bind_rows() |
To join two data frames based on a common column, you can use:
left_join(x, y, by)
where x and y are data frames, and by is the name of a column they have in common.
If there is only one column in common, and if it has the same name in both data frames, you can omit the by argument.
If the common column is named differently in the two data frames, you can deal with that by passing a named vector as the by argument. See below.
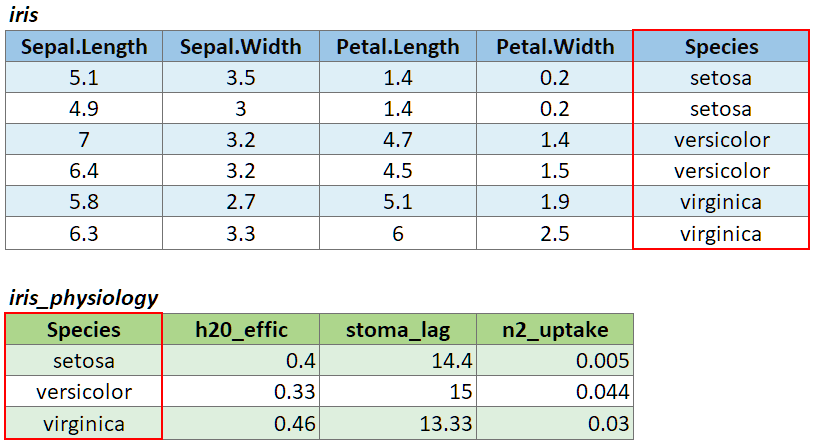
To illustrate a table join, we’ll first import a csv with some fake data about the genetics of different iris species:
# Create a data frame with additional info about the three IRIS species
iris_genetics <- data.frame(Species=c("setosa", "versicolor", "virginica"),
num_genes = c(42000, 41000, 43000),
prp_alles_recessive = c(0.8, 0.76, 0.65))
iris_genetics## Species num_genes prp_alles_recessive
## 1 setosa 42000 0.80
## 2 versicolor 41000 0.76
## 3 virginica 43000 0.65We can join these additional columns to the iris data frame with
left_join():
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species num_genes
## 1 5.1 3.5 1.4 0.2 setosa 42000
## 2 4.9 3.0 1.4 0.2 setosa 42000
## 3 4.7 3.2 1.3 0.2 setosa 42000
## 4 4.6 3.1 1.5 0.2 setosa 42000
## 5 5.0 3.6 1.4 0.2 setosa 42000
## 6 5.4 3.9 1.7 0.4 setosa 42000
## 7 4.6 3.4 1.4 0.3 setosa 42000
## 8 5.0 3.4 1.5 0.2 setosa 42000
## 9 4.4 2.9 1.4 0.2 setosa 42000
## 10 4.9 3.1 1.5 0.1 setosa 42000
## prp_alles_recessive
## 1 0.8
## 2 0.8
## 3 0.8
## 4 0.8
## 5 0.8
## 6 0.8
## 7 0.8
## 8 0.8
## 9 0.8
## 10 0.8
If you need to join tables on multiple columns, add additional column
names to the by argument.
Join columns must be the same data type (i.e., both numeric or both character).
There are several variants of left_join(), the most
common being right_join() and
inner_join(). See help for details.
If the join column is named differently in the two tables, you can
pass a named character vector as the by argument. A named
vector is a vector whose elements have been assigned names. You can
construct a named vector with c().
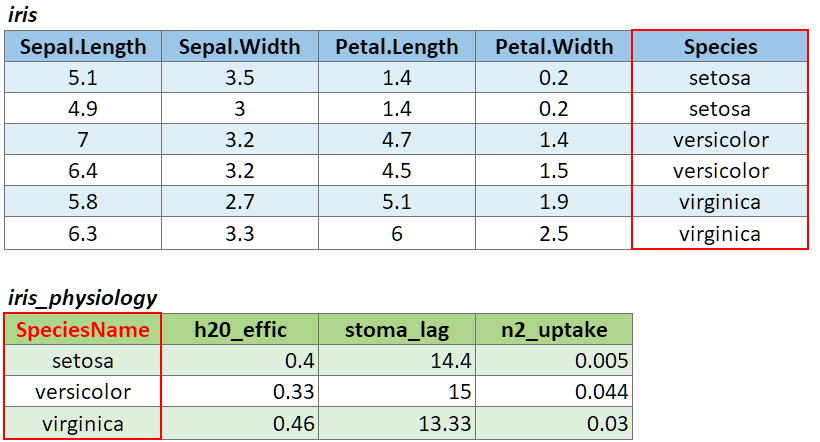
For example if the join column was named ‘SpeciesName’ in x, and just ‘Species’ in y, your expression would be:
left_join(x, y, by = c("SpeciesName" = "Species"))
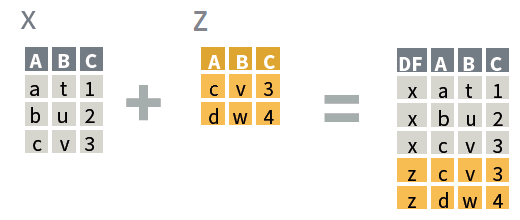
bind_rows(x, y)
where x and
y:

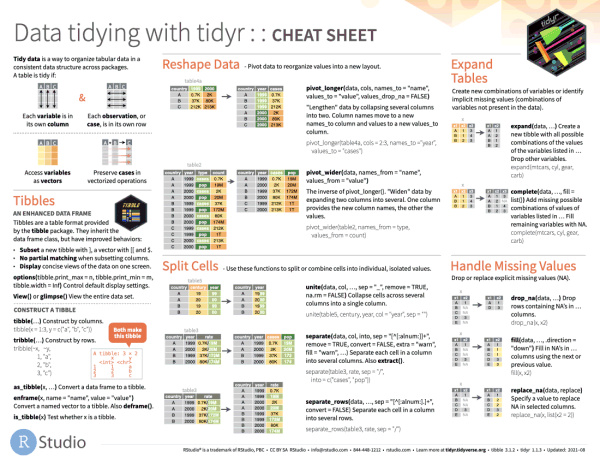
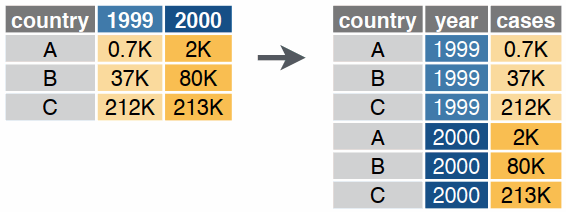
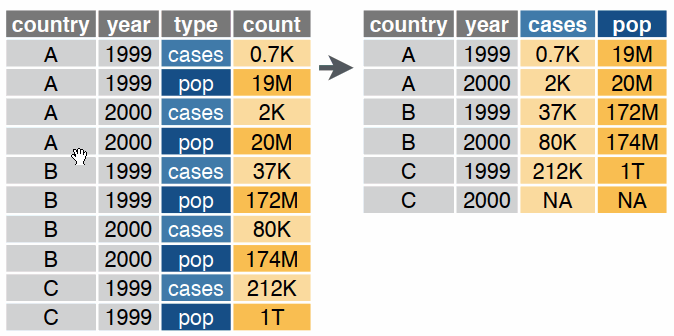
Reshaping data includes:
The go-to Tidyverse package for reshaping data frames is tidyr